Serializable transactions for peer-to-peer databases
Joel Gustafson and Raymond Zhong
2025-07-21
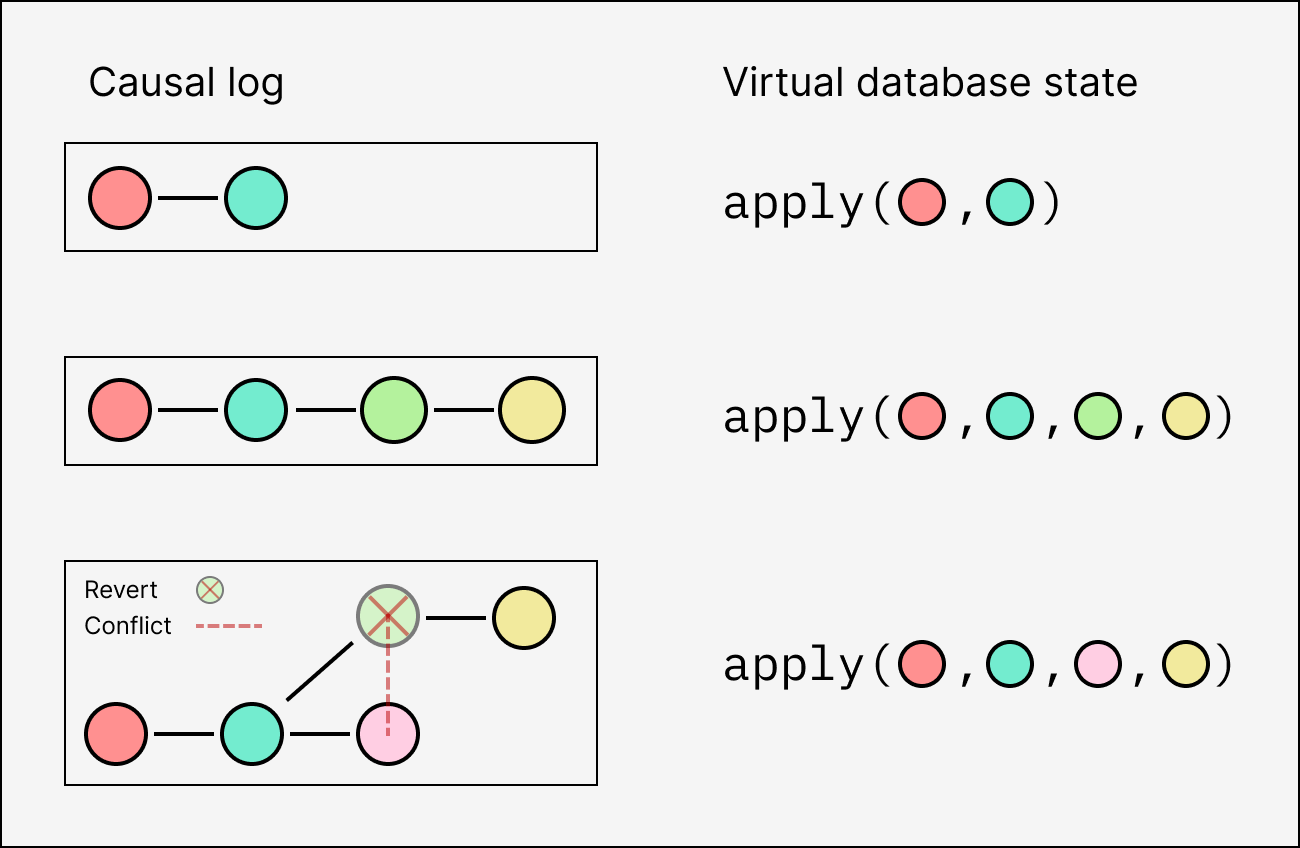
In this post we describe a novel design for serializable database transactions in multi-writer eventually-consistent environments. The basic idea is to allow transactions to be retroactively reverted, allowing peers to converge on a monotonic revert status for each transaction instead of syncing the database state directly.
This approach enables applications to enforce data constraints by writing regular imperative state transitions, surpassing intrinsic limitations of CRDTs. The tradeoff is tolerating database rollbacks in the event of concurrent conflicts. The rollback system is deterministic and can be used in peer-to-peer systems without any central authority.
#Table of Contents
#Background
If you have an app where multiple users interact with shared state, you have two options:
- centralize the state on a server that coordinates serial updates
- replicate the state everywhere, broadcast local changes, and merge asynchronously
Option #1 is the traditional client/server app architecture. Option #2 is appealing because it lets clients work offline, doesn’t involve blocking “coordination”, is compatible with decentralized architectures, and aligns with desirable values like user agency. This is a broad class of designs encompassing CRDTs, local-first software, “sync engines”, optimistic replication, and more.
Within this optimistic/replicated paradigm, maintaining a partially-ordered log of update operations is, in a certain sense, the best you can possibly do. This log resembles a Git commit graph, but where the branches are unnamed, and every commit merges all local unmerged branches together, if any. We call this a causal log to emphasize that it represents time in a distributed system.
See this previous post for a introduction to causal logs, and the sequel describing a peer-to-peer network protocol for reliable causal broadcast.
This is “the best you can do” because it records everything knowable about the relative order of the operations. Every eventually-consistent system reduces to it in one way or another. Some don’t need to store the operations forever, but if they did, it would look like a causal log.
If neither of two operations are ancestors of the other, we say they are concurrent. The fundamental problem for every eventually-consistent system is how to reconcile concurrent operations that have conflicting effects.
#Limits of CRDTs
So what can these operations do? The obvious strict requirement is convergence: two peers that have applied the same set of operations must have the same final state, even though concurrent operations might be applied in different relative orders on different peers.
We also need this result to be a valid application state. It’s not enough to validate that Alice and Bob’s concurrent operations are independently valid state transitions — we need to make sure merging preserves all the constraints that the application relies on. Finally, we also want merges to feel like a natural result within the application’s semantics.
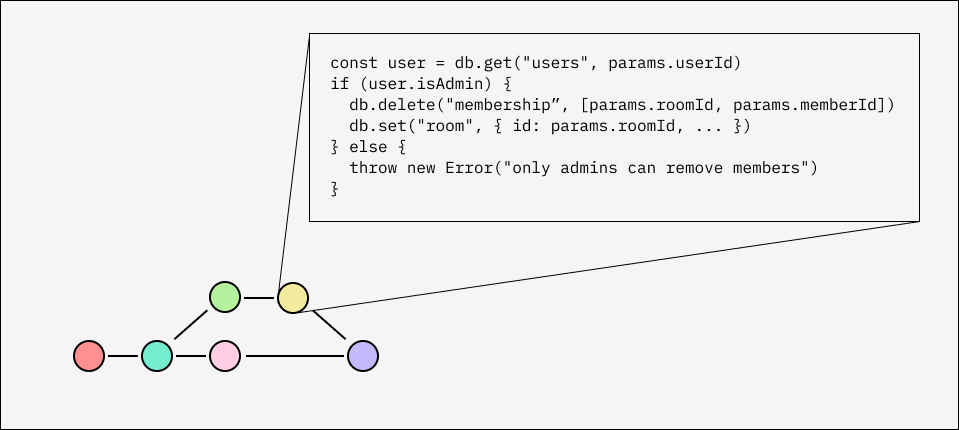
Text CRDTs have solved this for the collaborative document editing problem incredibly well, but applying CRDTs to other kinds of application state is difficult. The biggest reason is that CRDTs can’t enforce the constraints found in real-world applications. You can make a CRDT for “JSON documents”, but it’s not possible to constrain the document to a fixed JSON schema, even if all your users are well-behaved and only make locally valid operations.
At a theoretical level, this is a consequence of the CALM theorem, which tells us that coordination-free systems can only express monotonic computations. This excludes anything involving global information, or asserting something in the negative, such as:
- “a list can’t be empty”
- “a user can’t make more than 1000 posts per day”
- “only current admins can give or revoke admin status”
- “the sum of all account balances equals the total money supply”
As a result, CRDTs have remained limited to narrow parts of application state that are already naturally merge-friendly.
#Invariants, please
So what can be done? The prevailing wisdom is that applications can either
- fall back to using a central server
- require online peer-to-peer coordination, like distributed locking or consensus protocols
- carefully design a bespoke CRDT that provably preserves all of your app’s specific invariants (and then still fall back to a server when coordination is absolutely necessary)
- allow state to diverge in arbitrary ways, and have the end user manually merge branches through a version control UI
This is tough because, among other drawbacks, 3) and 4) still require a thorough understanding of your application’s data constraints, which are actually very hard to list off the top of your head. This makes bespoke CRDTs hard to design, and forces developers to adopt an awkward and unfamiliar approach to data modeling using “toolkits” of composable CRDTs.
The normal way developers like to write applications is to write correct state transitions in the form of database transactions. This defines the constraints inductively, without needing to express them as global predicates.
Wouldn’t it be nice if there were a way to write updates as regular database transactions executing arbitrary code, put them in a causal log, and still somehow have peers converge to a shared valid state?
What would we have to do to make that work?
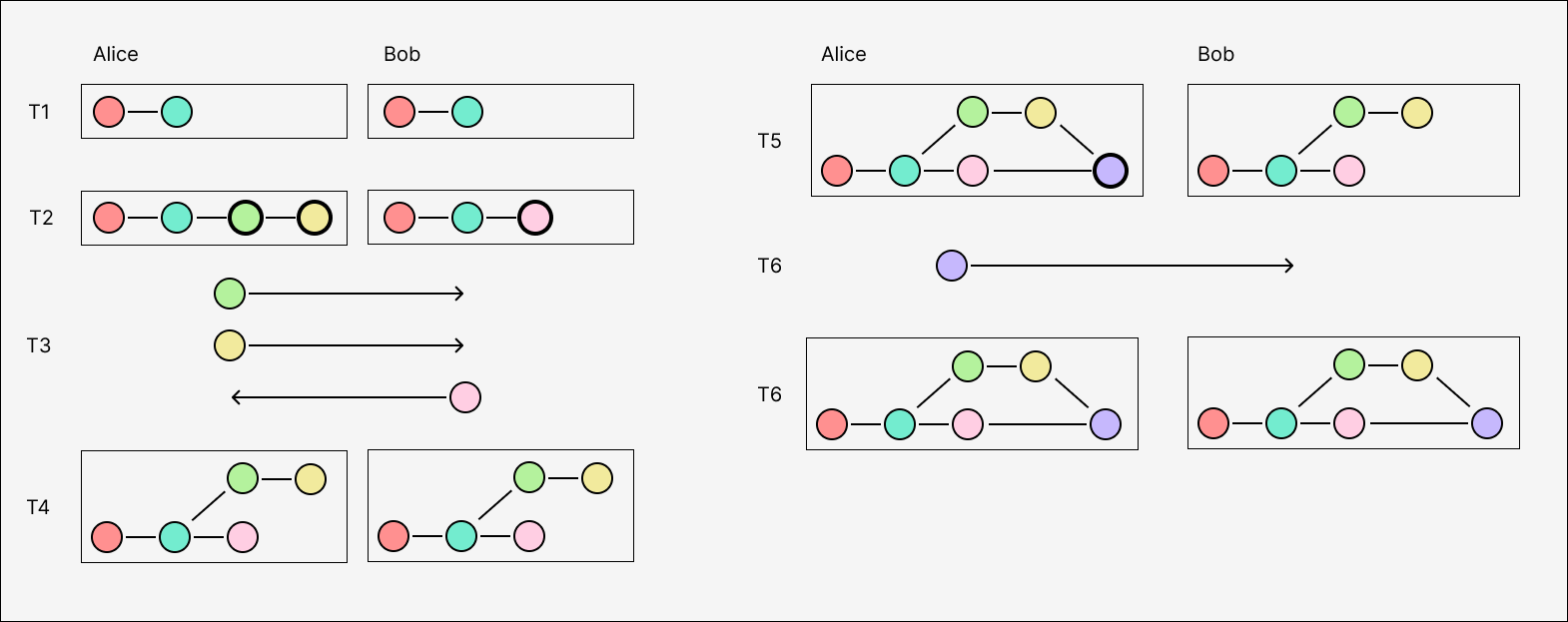
#Retroactive reverts
Let’s start by defining our goals. We want to use a causal log to distribute database transactions that can execute arbitrary computation, including reading and writing to relational tables. As before, we need to guarantee convergence over all possible local delivery orders of any given causal log. And now, for all our induced application invariants to actually hold, we must furthermore guarantee atomicity, consistency, and isolation for the transactions.
This is only possible at the expense of the remaining ACID property: durability.
In the eventually-consistent context, we can choose to trade off durability (or “finality”) and accept that some valid transactions will be retroactively reverted. This lets us transform the problem of merging arbitrary database states into simpler problem at a higher level of abstraction: converging on a revert state for each transaction in the log.
We call this approach eventually consistent rollback, or ECR.
In ECR, reverts are necessary because concurrent transactions might conflict: either writing to the same value (a write conflict) or reading a value that is overwritten by the other (a read conflict). If Alice and Bob commit conflicting concurrent transactions, they must both deterministically select the same single ‘winner’ once they eventually sync. If Bob’s transaction takes precedence, then he can just ignore Alice’s transaction when he receives it, while Alice has to revert hers (and atomically revert all of its effects) before applying Bob’s.
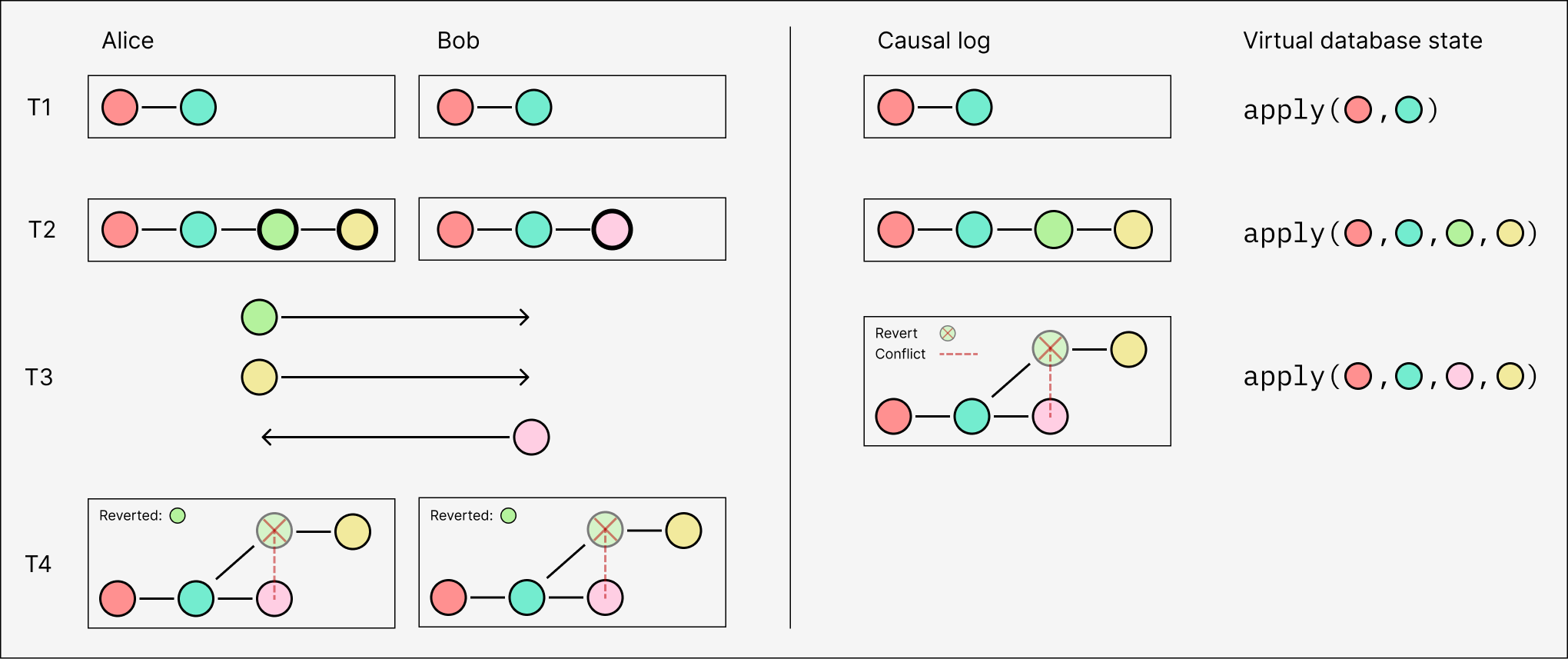
We will examine conflicts and reverts in detail in later sections. For now, just note that not all concurrent transactions conflict — only ones that actually write to the same values, or read a value overwritten by another. If Alice and Bob are operating on disjoint data, or only read from shared data, or read from shared data while writing to disjoint values, there is no conflict and the transactions can be safely applied in any order.
#ECR ergonomics
This might all sound crazy, and it is. So before going any further, let’s try to situate ECR within the landscape by comparing some of its properties to CRDTs, blockchains, and databases. We’ll also talk about how it might feel to use an ECR database, just to convince ourselves that it’s plausible.
#ECR vs CRDTs
CRDTs are good for values that have natural commutative merge semantics within the application. For values that can’t be deeply merged, last-write-wins (LWW) registers serve as a fallback.
When Alice and Bob write to the same LWW register at the same time, the effect is that one of their writes “clobbers” the other. If there are multiple LWW registers, syncing can leave them in a mixed or interleaved state, potentially breaking constraints like foreign key references.
One way of using ECR is to generalize LWW registers by letting the developer bundle multiple LWW effects together into atomic transactions. All the effects within a transaction will get reverted together if any of them are superseded by another write.
#ECR vs blockchains
ECR is similar to smart contracts in that transactions can execute arbitrary code, including reading data from global state. Both systems guarantee that, at all times, the database state is equivalent to the serial execution of some sequence of valid transactions, although which exact sequence is considered “current” can change.
Revert mechanics are related to the concept of finality in blockchains. Blockchains only provide probabilistic durability guarantees for transactions — approaching certainty as more and more blocks are added to the chain, but always theoretically subject to re-organization or omission if a longer chain is surfaced by the network. Modern blockchains avoid re-orgs by heavily penalizing validators which vote for multiple concurrent chains, but finality is only as strong as a network’s validator set, and its ability to avoid partitions and stay online.
Nevertheless, while blockchain validators adhere to a strong sense of finality, many blockchain clients do not: different services like exchanges and wallets may choose their own “block height” thresholds for determining if a transaction has committed.
Similarly, ECR has a flexible sense of durability. On one extreme are “forgiving” environments that welcome long offline periods, where syncing might necessarily revert months-old local transactions. But ECR could also be used in conjunction with timestamping services to arbitrate conflicts within a smaller moving window, while guaranteeing finality after a period of time.
#ECR vs databases
Many databases (like Postgres) already use MVCC or other optimistic strategies instead of locking, and only check for conflicts between transactions at commit time. If conflicts are detected between concurrent transactions, one of them is rolled back.
This behavior fits within application developers’ existing mental models, since they already can’t assume that commits will succeed. You already have to handle the error case, either by re-trying the transaction, or reporting the error back to the user through the UI, or something else specific to the application.
With an ECR database, commits are guaranteed to succeed locally, but might be reverted in the future. Handling retroactive reverts is not all that different — simply re-trying the transaction is often an appropriate response, and could be automated for some operations. The reverted transaction is still persisted in the log, and can be used to inform how the app reacts, or made available to the user for manual re-application.
Using ECR means handling revert events instead of commit failures
More broadly, modern web apps have converged on the React paradigm of “UI as a pure function of state”, and now data fetching libraries and sync engine frameworks are pushing this even further to let developers define (some) state as a pure function of their database using live queries. This means that reverting one causal branch and hopping to another doesn’t necessarily require special handling for each reverted transaction individually; the developer could sit back and let the app re-render from the new database state automatically.
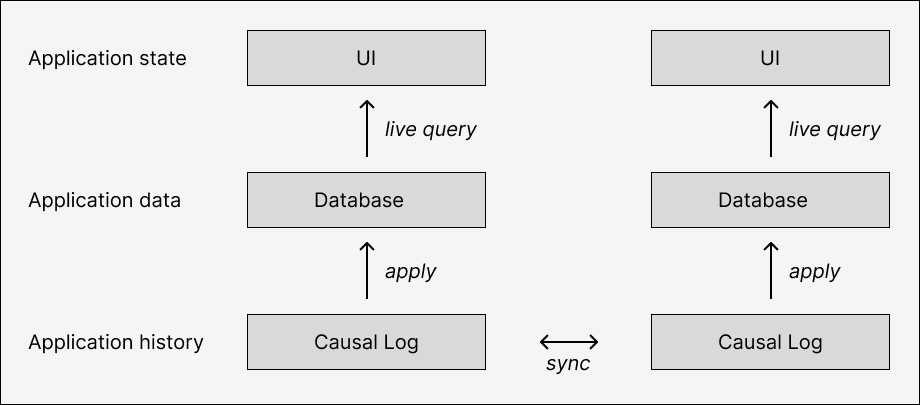
Of course, real apps would still need to communicate some information about revert and sync status to the user, and pioneer new design patterns that minimize surprise during revert transitions. But this seems less imposing than, for example, a full-blown version control UI for the entire application.
#Design
Alright! Having defended the idea as at-least-not-totally-insane, let’s get into how to implement an ECR system at-least-not-totally-inefficiently.
In particular, how do we achieve this:
… without literally replaying the log every time a transaction gets reverted?
The one major simplification that we will make is to restrict reads to individual get queries, and only by primary key. No counting, aggregating, filtering, or iterating. We’ll still be able to make arbitrarily complex relational queries from the outside (e.g. for rendering the UI), just not from inside the update operations.
Here’s how our operations look as a simple TypeScript interface.
interface DB {
get(table: string, key: string): Record<string, any> | null
set(table: string, key: string, value: any): void
delete(table: string, key: string): void
}
type Transaction = (db: DB, params: Record<string, any>) => void
type Operation = { txn: Transaction; params: Record<string, any> }Naively applying these transactions directly to a database won’t be convergent, since some operations will be concurrent and peers might apply them in different orders. Instead, we will intercept the reads and writes, executing transactions inside a special time-traveling runtime that gives us convergence, atomicity, isolation, etc.
#Snapshot reads
Let’s start by considering reads. Transactions can have arbitrary code, so if they’re going to execute deterministically on all peers, it’s crucial that every db.get(...) returns exactly the same thing regardless of any other concurrent transactions that have already been applied.
Furthermore, this needs to be the current value observed by the peer who created the operation at the time they created it. Otherwise, actions taken in response to some piece of state displayed in the UI could end up executing with a reference to a different version of that state!
So, how do the other peers find the correct value for db.get(...) to return?
In a causal log, every operation has zero or more parents, which determines a unique transitive ancestor set. The transitive ancestor set gives us a greatest common denominator to work with — causal delivery guarantees that before we apply an operation, we will have already applied all of its ancestors. This transitive ancestor graph is also a snapshot of the log that the peer who created the operation had at the time they created it, which is exactly what we need.
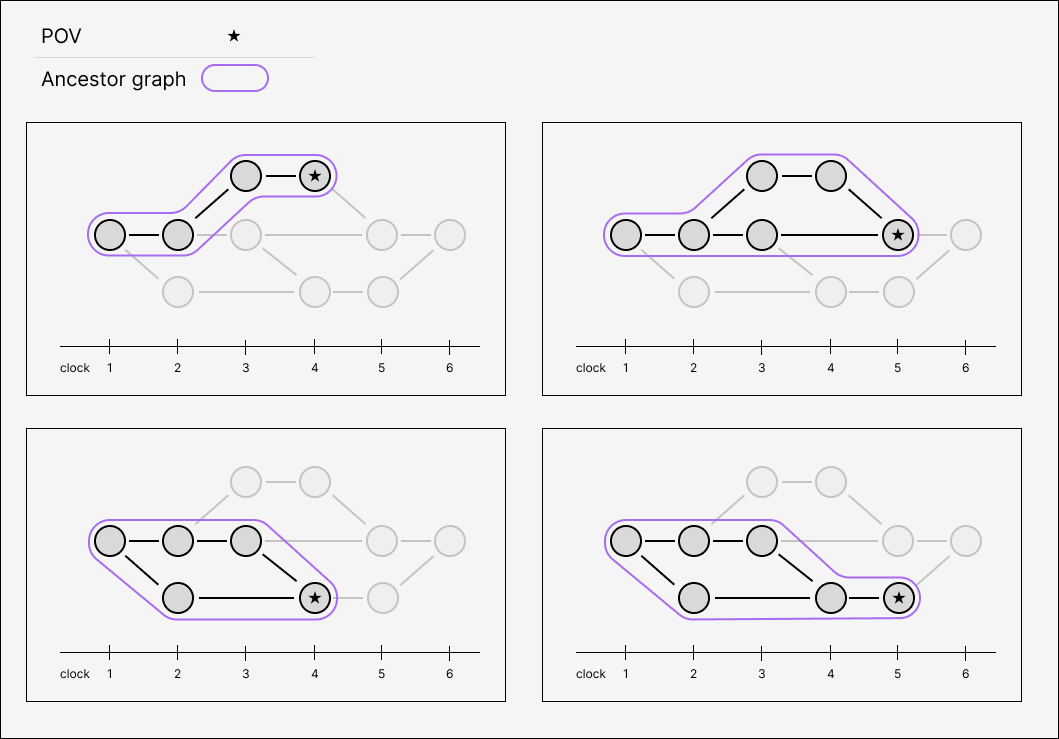
This gives us the general principle for database reads:
Each transaction sees a point-in-time snapshot induced by its transitive ancestors.
You can think of this “the database we would get if we were to replay just the transitive ancestors from scratch in causal order”, although we don’t want to actually do that in practice.
Point-in-time queries are a feature offered by a few existing databases, like Datomic and SpacetimeDB, but here we’re talking about something even stranger, since for us time isn’t linear. The runtime needs to resolve reads from the point of view of arbitrary places in the causal log. We will refer to things that are relative to a certain PoV as subjective. The runtime needs to implement subjective reads.
We can do this by storing every historical write in a table, along with a transaction id that begins with the operation’s logical clock, so that they sort in causal order (more detail here). Whenever we execute a transaction, we collect all the calls it makes to db.set(...) and db.delete(...) and persist them here.
CREATE TABLE ecr_writes (
txn_id TEXT NOT NULL,
record_table TEXT NOT NULL,
record_key TEXT NOT NULL,
record_val BLOB -- null for deletes
);
CREATE INDEX write_txn ON ecr_writes (record_table, record_key, txn_id);Now, when we need to answer db.get(table, key) from the perspective of a specific transaction id , we can iterate over the history of the record in reverse causal order.
-- selectWrites
SELECT txn_id, record_value FROM ecr_writes
WHERE record_table = ? AND record_key = ? AND txn_id < ?
ORDER BY txn_id DESC;But this is not enough - we also need to filter for just the transactions that are one of ’s transitive ancestors. This is the graph reachability problem, which has a wide range of solutions with different tradeoffs between runtime and index size. A good balance is a hierarchical skip-list, which takes space and time for both updates and queries.
Lastly, we also need to skip over any transactions that are reverted. We haven’t defined what this means yet, so we’ll use a placeholder isReverted function. Notice that this is subjective revert status: whether the transaction is reverted from ’s point of view, considering only ’s transitive ancestors. This is why we can’t store is_reverted: boolean in the writes table, and why we can’t afford to ever materialize these snapshots in their entirety.
In the end, our virtual “point-in-time database snapshot” is just a function for dynamically resolving subjective reads.
// our `get`, `isAncestor`, and `isReverted` methods are all
// subjective w/r/t to a certain point of view
interface PoV {
txn: string | null // current transaction id, or null for the global PoV
parents: string[] // current transaction parents, or all concurrent heads
}
function get(pov: PoV, table: string, key: string): Record<string, any> | null {
for (const write of selectWrites.iterate(table, key, pov.txn)) {
if (!isAncestor(pov, write.txn_id) {
continue
}
if (isReverted(pov, write.txn_id)) {
continue
}
return decode(write.record_value)
}
return null
}Neat!
#Conflicts
What are the specific conditions that cause a transaction to be reverted? And how do we implement this subjective isReverted efficiently?
Reverts are caused by conflicts. When two transactions conflict, at most one of them can be included in a virtual database snapshot. To achieve serializable transaction isolation, we need to detect two kinds of conflicts:
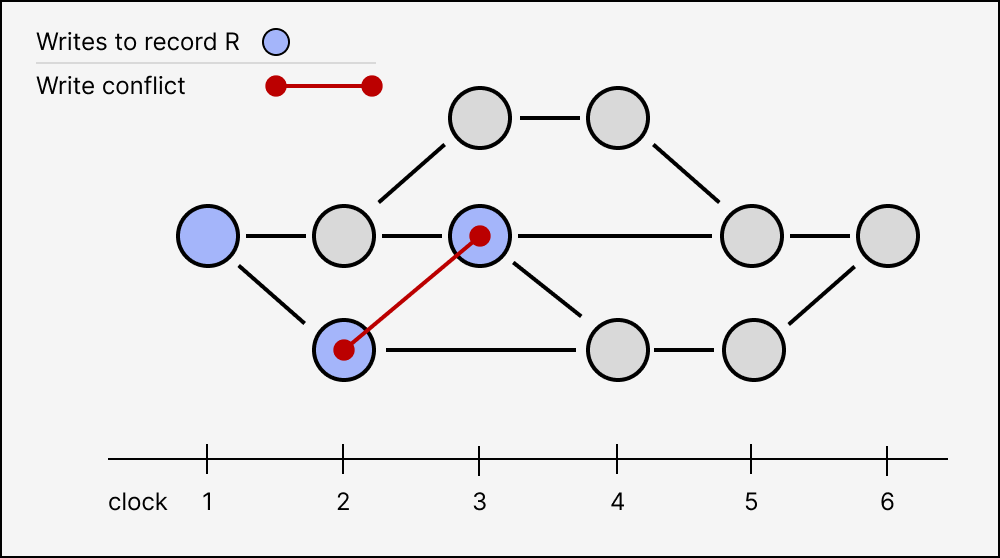
- Write conflicts, where two concurrent transactions write to the same record. Write conflicts are symmetric, so the best we can do is have the higher transaction ID take precedence over the lower transaction ID. These are also known as write-write conflicts.
- Read conflicts, where a transaction reads from a record that is concurrently written to by another transaction. Although we could use transaction IDs again, it will be more convenient to say that the write will always take precedence over the read. Writes typically represent higher-priority, more-privileged actions than reads.
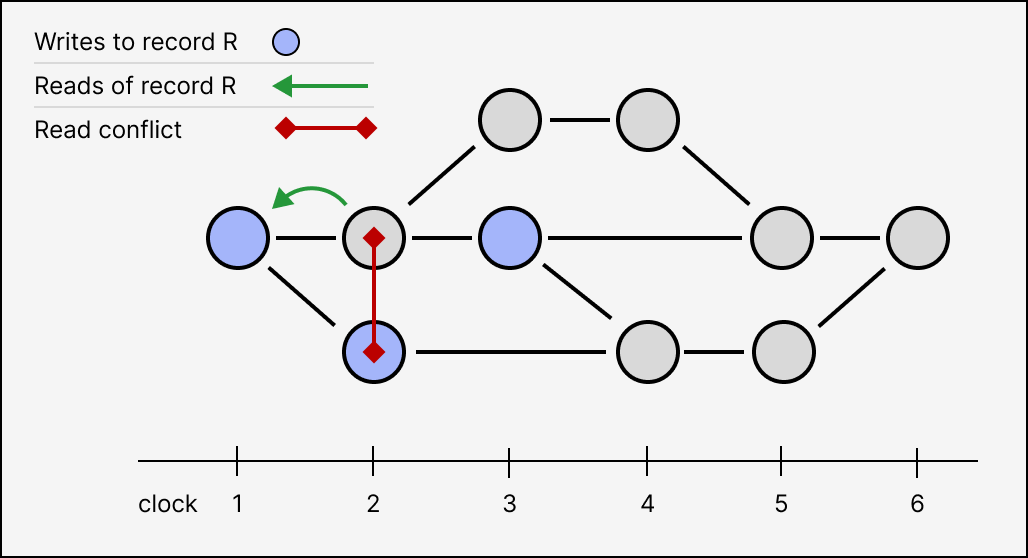
Read conflicts are also called read-write conflicts or write-read conflicts, depending on the perspective of a specific local total order. Since there is no canonical total ordering in a causal log, we just refer to them collectively as “read conflicts”.
If we were to ignore read conflicts, and only consider concurrent writes as conflicts, we would have, we would have snapshot isolation. This is the default in many databases like Postgres, but allows for some undesirable phenomena like write skew. By detecting read conflicts from both the reader’s and the writer’s perspective, we eliminate the possibility of write skew and achieve full serializability.
#Dependencies
There is also one more reason a transaction can be reverted: when it reads a value written by another reverted transaction. Every db.get(...) creates a dependency between the transaction that wrote the resolved value and the transaction calling db.get. If the writer is reverted due to a write conflict, read conflict, or one of its own dependencies, then the reader must also be reverted.
This is a “minimal” concept of dependency, where we know with certainty that the reader transaction needs to be reverted if the writer is reverted. On the other extreme is the partial order given by the causal log, which is the “maximal” concept of dependency capturing everything that could possibly have influenced a given transaction.
There could also be semantic dependencies between the extremes, that are not captured by db.get(...) calls but still ought to cause a revert — maybe the user only took a certain action because they observed the effect of another transaction. If we wanted, we could incorporate a mechanism for creating additional dependencies explicitly, although this would induce a higher rate of conflicts.
#Conflict sets
All together, evaluating whether a transaction is reverted w/r/t PoV involves checking:
- for every record written by , are there any writes to included in and concurrent to with higher transaction IDs?
- for every record read by , are there any writes to included in and concurrent to ?
- are any dependencies of reverted w/r/t ?
In order to identify these conflicts efficiently, we need some way of indexing groups of concurrent writes. We begin by generalizing write conflicts between individual transactions into conflict sets containing many transactions.
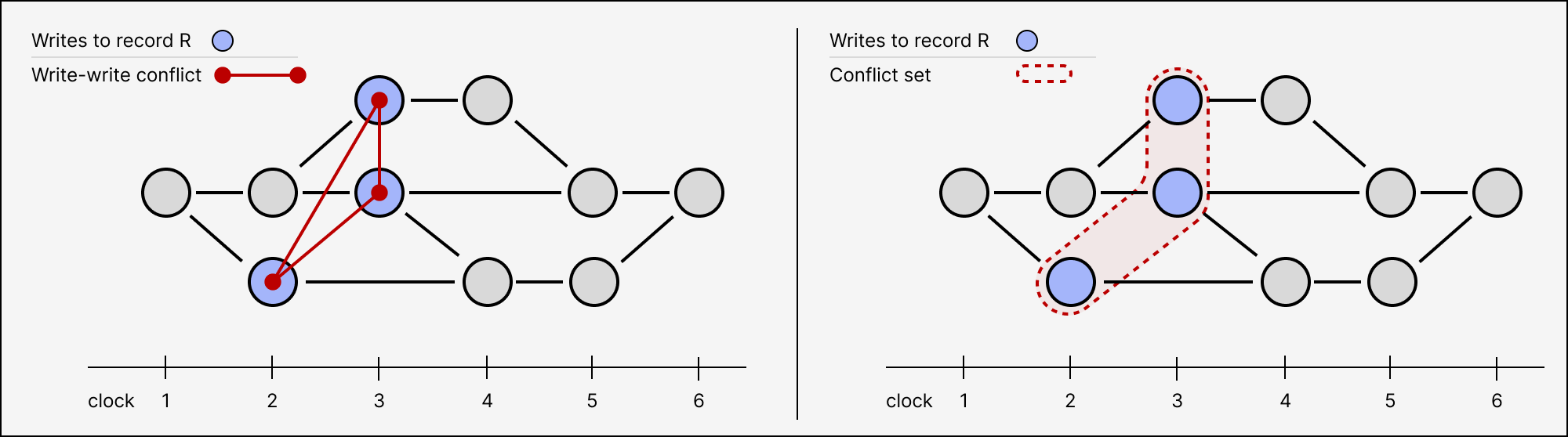
A conflict set for a record is a set of mutually concurrent writes. Conflict sets form an indexed sequence of antichains defined inductively for each record.
- The first conflict set for a record consists of all the writes that have no writes to in their transitive ancestors
- The th conflict set for a record consists of every write that
- is a descendant of one or more members of , and
- is not a descendant of any other write descending from a member of
Here’s a larger example of many writes, grouped into indexed conflict sets:
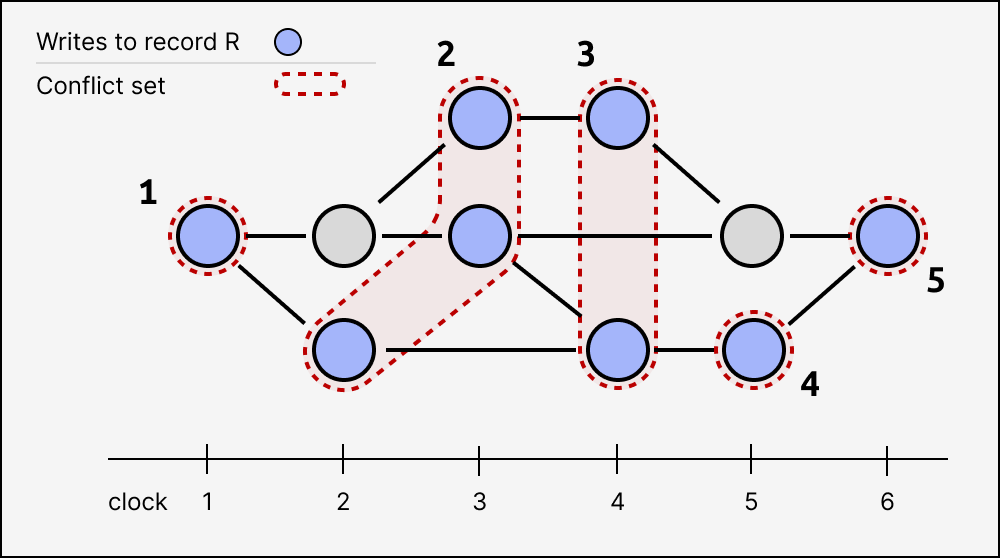
Of course, a transaction might write to several records, each of which has their own independent conflict set structure.
Here’s another example with two long parallel branches:
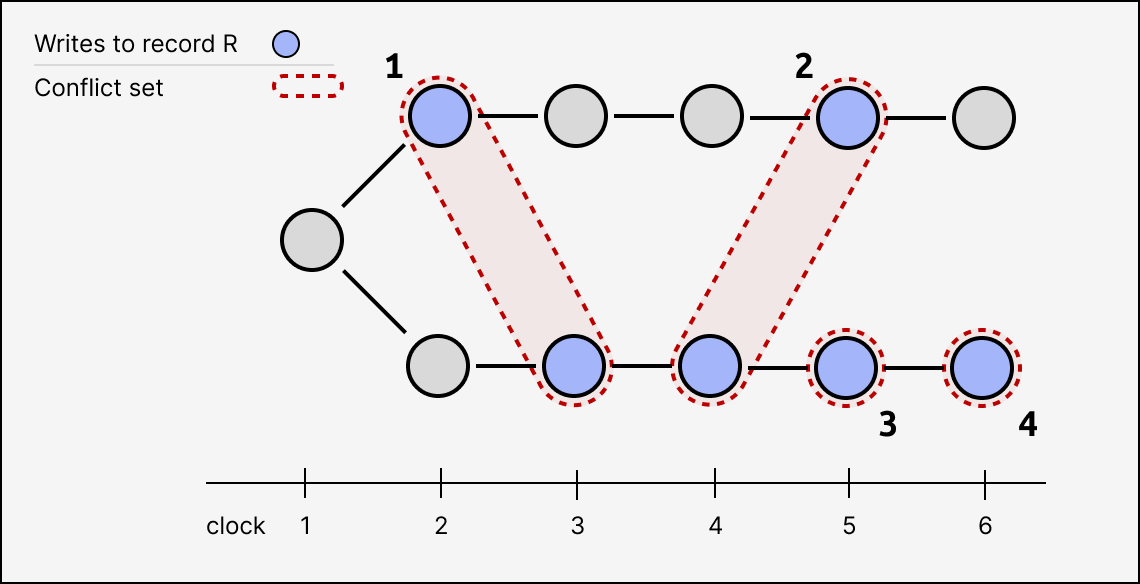
Notice that the conflict set index for each write is a deterministic product of each transaction’s ancestor graph. If Alice and Bob created the top and bottom branches (respectively) in isolation, they wouldn’t need to communicate to compute the conflict set index for each of their writes, and those indices wouldn’t change after they sync their logs. They will always agree on how to group their respective writes into the same conflict sets.
Which conflict set a transaction belongs to is an objective fact. Which members a conflict set has is subjective. From any given place in the log, only the transitive ancestors are “visible”, so a particular conflict set might have several members from one PoV, but only a single member from another PoV.
Since conflict set indices are defined inductively, computing them for every new transaction’s writes is easy. Let’s say we store them as an integer csx in our writes table:
CREATE TABLE ecr_writes (
txn_id TEXT NOT NULL,
record_table TEXT NOT NULL,
record_key TEXT NOT NULL,
record_val BLOB, -- null for deletes
csx INTEGER NOT NULL
);
CREATE UNIQUE INDEX write_txn ON ecr_writes (record_table, record_key, txn_id);
CREATE UNIQUE INDEX write_csx ON ecr_writes (record_table, record_key, csx);#Greatest elements
Writes within a conflict set are all in conflict with each other, and there is a unique subjective greatest element (ordering by transaction ID) that takes precedence over the others.
Here, the figure on the left shows the ordering of elements within conflict sets, and the figure on the right shows the subjective greatest element from two different points of view.
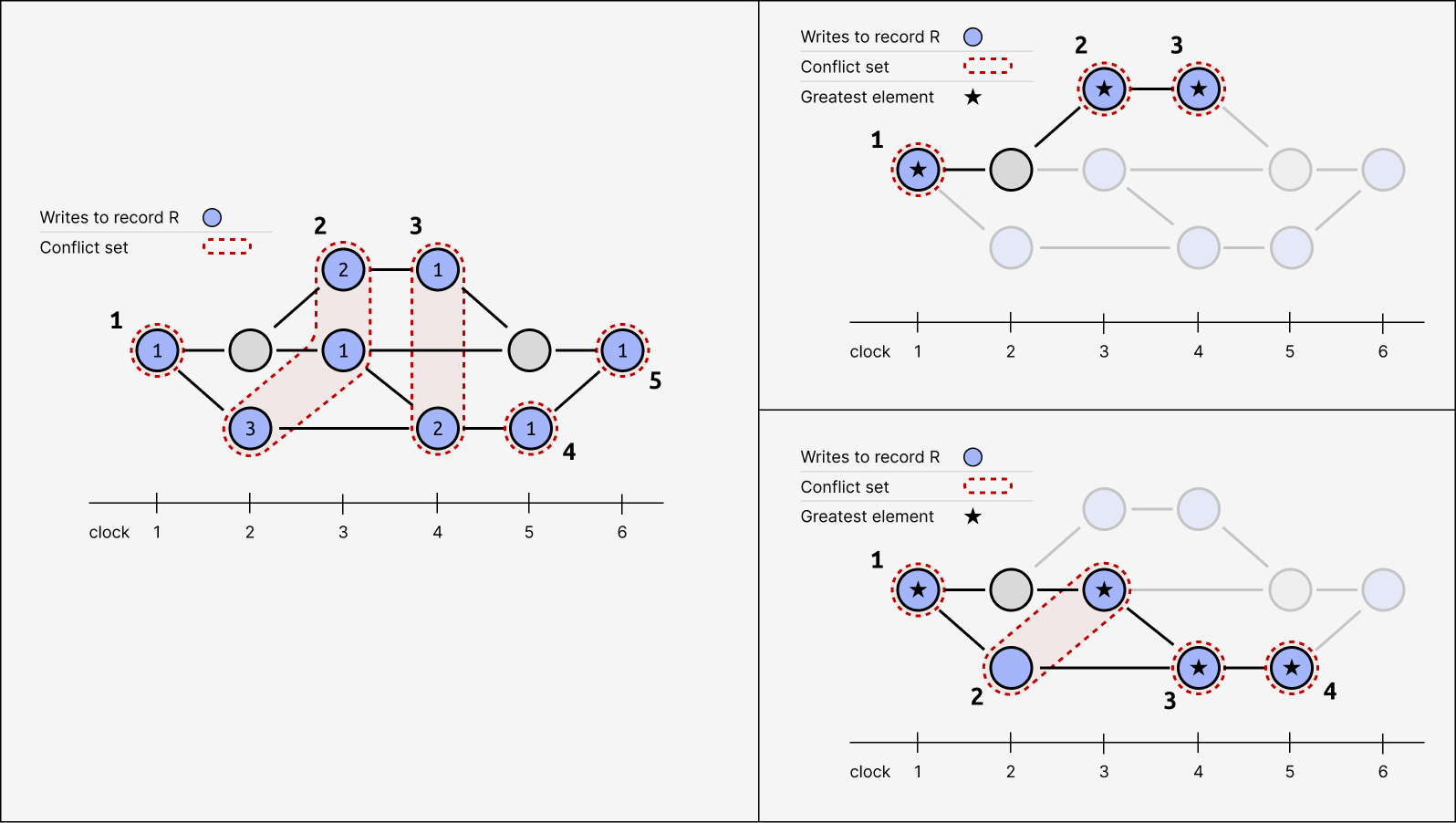
#Identifying write conflicts
This immutable csx is what lets us query for write conflicts. For every record that a transaction writes to, we can now select all members of the same conflict set with a higher transaction ID (that are also ancestors in the causal log).
-- selectWriteConflicts
-- as before, we still need to filter these results using isAncestor
SELECT txn_id, csx FROM ecr_writes
WHERE record_table = ? AND record_key = ? AND csx = ? AND txn_id > ?#Identifying read conflicts
We can identify read conflicts in essentially the same way. When evaluating whether a transaction is reverted w/r/t some PoV , we only need to check for concurrent writes to the records that read from. We don’t need to check for existing reads concurrent to ’s writes, since writes always supersedes reads.
We record each of ’s db.get(table, key) calls in an ecr_reads table, storing the record , the transaction ID of the resolved value, ’s transaction ID, and a reader_csx index identifying the greatest conflict set for found in ’s ancestor graph.
CREATE TABLE ecr_reads (
record_table TEXT NOT NULL,
record_key TEXT NOT NULL,
writer_txn TEXT NOT NULL,
reader_txn TEXT NOT NULL,
reader_csx INTEGER NOT NULL
);Then we can evaluate w/r/t some whether an arbitrary transaction is reverted due to a read conflict by selecting all of its reads, and asserting that the greatest element of the subsequent reader_csx + 1 conflict set is a causal descendant of .
#Compressing transitive dependencies
The ecr_reads table also gives us explicit “dependency links” that we could recursively traverse to complete our isReverted implementation. However, this means that checking the revert status would be slower than linear in the number of operations in the log. We need a better way.
The original reason that we can’t have a simple is_reverted: boolean property on each transaction is that we need to be able to evaluate revert status from arbitrary subjective perspectives. If a peer suddenly receives a months-old message whose only parent is buried deep in the past, it must be able to efficiently evaluate its db.get(...) calls from the perspective of that single parent’s ancestor graph.
But the perspective is the only thing that changes, so we can pre-compute as much as possible. One approach is a cause/effect table:
CREATE TABLE ecr_reverts (
effect_txn TEXT NOT NULL,
cause_txn TEXT NOT NULL
);
CREATE UNIQUE INDEX ecr_revert_causes ON ecr_reverts(effect_txn, cause_txn);
CREATE UNIQUE INDEX ecr_revert_effects ON ecr_reverts(cause_txn, effect_txn);For each transaction T, we can maintain a list of causes: other transactions which, if visible from , will cause T to be reverted w/r/t . Then evaluating revert status amounts to using the ancestor index to check if any of the causes are ancestors of .
Whenever we apply a new transaction T, we add the necessary cause/effect entries. If T writes to a record R whose conflict set already has two members, one “inferior” (with a lower transaction ID than T) and one “superior” (with a higher transaction ID than T), then we add two cause/effect entries:
INSERT INTO ecr_reverts(effect_txn, cause_txn) VALUES (:T, :superiorTxnId);
INSERT INTO ecr_reverts(effect_txn, cause_txn) VALUES (:inferiorTxnId, :T);Similarly, when a read conflict is created (from either side), we add an entry with the writer as the cause and the reader as the effect.
But how does this solve our dependency iteration problem? It would seem that to handle recursive dependencies, we would need to create a separate entries for all transitive dependencies, creating a space explosion.
The key insight with the cause/effect table is that causes can be consolidated. Suppose A and B are both causes of the same effect E, and A is an ancestor of B. Every PoV that includes B must necessarily include A, so the E ← B entry is redundant and can be pruned. The causes for each effect can be kept to a minimal mutually-concurrent set, which prevents transitive dependencies from accumulating.
#Monotonicity of reverts
The cause/effect index also highlights an important property of the rollback system. Since the causal log is append-only, any transaction that is visible from one PoV is guaranteed to be visible from all descendant PoVs. This means that as the log grows, the set of revert causes for a given transaction will only ever grow, and never shrink. As a peer’s global PoV evolves, transactions only get reverted once, and can never become un-reverted afterwards.
As the log grows, transactions only become reverted once, and never become un-reverted
This is a reassuring guarantee. The database can roll back time, but it will never jump back and forth, only settle monotonically into a maximally consistent common denominator.
#Practical Considerations
Rollbacks are a strange, under-explored corner of distributed system design space. ECR is similar in some ways to MVCC transactions, blockchain state channels, and how massively multi-player video games use client-side prediction. But whether it can be a useful component of end-user applications requires more study.
#Prior work
To consider prior work, ECR closely resembles systems like Replicache or Zero, which implement a similar transactional conflict resolution algorithm where any user can execute custom mutations on a database, and conflicting mutations are rolled back and reexecuted. These approaches are now more broadly implemented in databases like Convex.
However, unlike these systems, our algorithm does not assume the existence of a central coordinating server, and allows rollbacks to reach back arbitrarily far in time. (We also do not specify a reexecution strategy in our work to date.)
#Client-side and peer-to-peer applications
As one example, over the last half year, we ported a real-time strategy game (a web-based game similar to Civilization) to a peer-to-peer ECR runtime that we’ve been developing. We moved the existing game logic, which was written in client-side TypeScript, into eventually-consistent transactions, with approximately two days of straightforward work.
After the port, gameplay was indistinguishable from before. The only added requirement was that it was now necessary to sync the entire history of each ECR transaction log. Conveniently for us, the application was naturally partitioned into a separate log for each game - and games were short enough (30-60 minutes) that the log was unlikely to grow beyond a manageable size.
The pattern here is basically using ECR for individual objects in an object sync engine, where each object is fully synced between clients.
#Long-lived and provable applications
Still, if we wanted to have longer-lived objects, the log might grow to a size where syncing the entire history becomes impractical. This is a more general issue with client-side, event-sourced databases. At the very least, it would be necessary to introduce some form of log compaction, e.g. one like Automerge’s Sedimentree, which identifies “levels” of past actions that can be chunked and treated as large atomic blocks.
For long lived, peer-to-peer applications, it might be necessary to have proof that the compaction was performed correctly. Practically, this implies writing our rollback application inside a ZK-friendly virtual machine, and constructing a zero-knowledge proof that the transaction was executed correctly. This is far outside the scope of this post, but fortuitously, a variety of ZKVMs now exist that can prove the execution of Rust, WASM, and other languages.
#Adding finality
Another consideration worth revisiting is that the ECR system we have proposed does not, by itself, have any finality properties, meaning that arbitrary subsets of the application state can be rolled back at any time.
To start, this means that applications implementing ECR might want to guide users to only interacting with the application while they are online, to avoid unexpected conflicts that might roll back users’ work. It also restricts the environments where ECR can be safely used to ones with cooperative users and non-adversarial interactions.
On the other hand, programs written in this paradigm can be run as fully trustless open networks that do not depend on any central coordination, which is a useful property in itself.
For non-cooperative applications or simply applications that would be easier to use with finality guarantees, we could instead implement ECR in conjunction with a finality layer.
This might resemble a long-lived state channel that settles to a blockchain, where each user’s actions confirm other users’ previous actions. As long as users do not roll back their own interactions, this would create a monotonically advancing state machine that can be occasionally finalized back to the underlying settlement layer.
#Conclusion
Despite these open questions, the ECR algorithms we described above make it possible to have long-lived operation histories, which can be cleanly and deterministically reconciled between any set of peers.
And the bar isn’t that high: everyone wants seamless local-first applications, but CRDTs are incredibly limiting in the operations that they allow. Supporting concurrent writes for an application with any complexity will always involve some combination of automatic and manual merging (e.g. letting the user re-apply reverted operations from the UI). The question is what kinds of abstractions will emerge to organize this process between the user, application, and database.
At the very least, it’s encouraging that the space is so big. There aren’t only narrow categories of ways to resolve concurrent conflicts. Even theoretical results like the CALM theorem are relative to system boundaries that can be redrawn.
We’re using ECR inside the Canvas runtime, building on our previous work on reliable delivery for causal logs. Canvas is a programmable replicated runtime and database, with an interface similar to Durable Objects. If that sounds like something you’re interested in building on, come chat with us on Discord or explore the docs site.