Syntax highlighting on the web
Joel Gustafson / Posts / 2022-05-31
How does syntax highlighting work?
In IDEs, syntax highlighting has traditionally been implemented in a mode-based pattern matching approach. Each language "grammar" defines a set of scopes, regular expressions that match different kinds of tokens in each scope, and inclusions of scopes inside other scopes. The capturing groups in the regular expressions are then associated with names in some taxonomy that themes interface with.
I put "grammar" in quotes because they're very different from actual formal grammars (ABNF etc). Code editing as we know it is really a stack of several mostly-independent features, each of which has different priorities and ends up involving a different version of "parsing". IDEs mostly want syntax highlighting to be fast and forgiving. We expect our tokens to be colored "correctly" even in invalid/intermediate states, and we expect highlighting to happen basically instantly. This means that lots of systems converged on loose regex-based approaches that could identify keywords and operators and atoms without needing to parse the source into an actual AST.
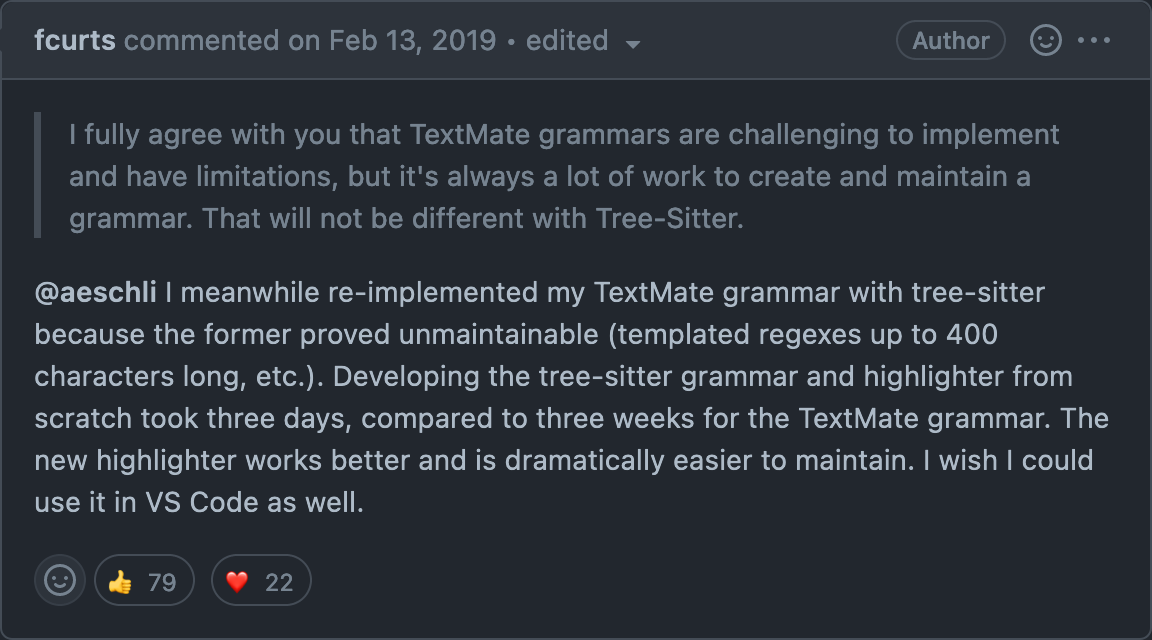
One downside to mode-based pattern matching is that it is fundamentally a very coarse version of parsing, and getting grammars to distinguish between things like function calls and variable names can be prohibitively complicated. Writing and maintaining these grammars is also a massive pain, because it requires thinking about the syntax of the language in unintuitive ways. This blog post is a good summary of just how much cognitive overhead there is in learning to write TexMate grammars, which are what VS Code uses. It doesn't help that the TexMate grammar format is itself largely undocumented.
Here's VS Code team member @alexdima commenting on the limitations of TexMate grammars.
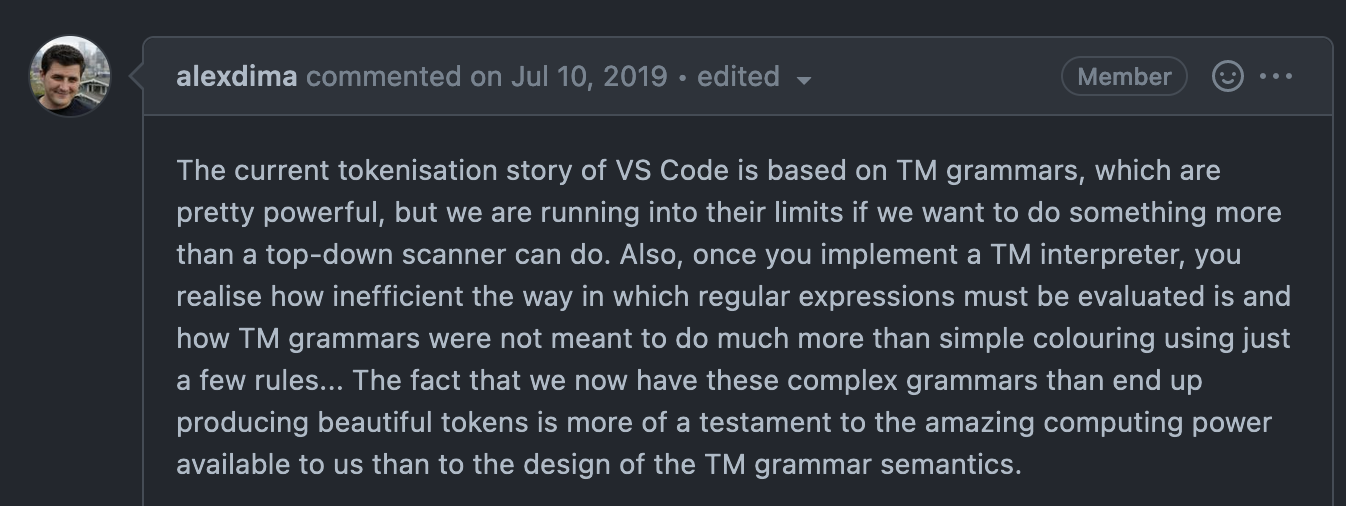
@alexdima also included a screenshot of VS Code's TexMate grammar for TypeScript which is just too funny not to pass on.

Clearly this is not ideal.
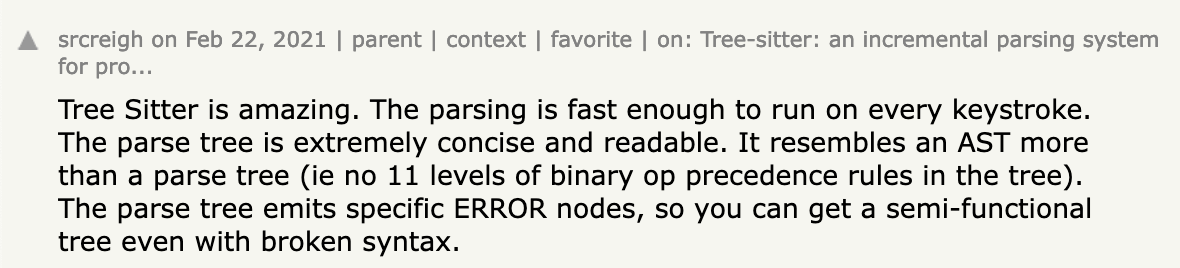
In 2018, Max Brunsfeld on the Atom team at GitHub released tree-sitter, a brand new parsing system designed to serve as a modern foundation for code analysis and syntax highlighting in editors.
tree-sitter is a big deal. It's fundamentally different than the mode-based pattern matching that everyone else has been doing, and acts much more like a real parser that gives you an traditional AST to work with. The technical details are way beyond me, but it seems like Max was able to apply some modern research on incremental parsing to hit a sweet spot of performance, generality, and error tolerance that just wasn't possible with parser generators before. Also it's written in Rust so Hacker News automatically loves it.
You still have to write a grammar for each language, but they're structured like the AST, and as a result can be used for other editor features beyond syntax highlighting (the release blog post calls out code folding but lots more is possible). tree-sitter grammars are simultaneously more concise and more powerful than mode-based pattern matching: we obviously shouldn't take LOC too seriously, but tree-sitter-javascript/grammar.js is "just" 1156 lines while VSCode's JavaScript TexMate grammar is over 3500. More importantly, it's not mostly escape characters.

It can't do everything. We still need language servers for autocomplete and type-checking and whatnot, but it does dramatically increase the degree of structure available to IDEs without calling out to separate processes.
It's 2022 now, and Atom is mostly dead, but tree-sitter lives on: GitHub uses it for syntax highlighting and the jump-to-definition feature (!!), SemGrep uses it for static analysis, and there's lots of ongoing discussion about integrating it into other IDEs.
But what does any of this have to do with the web? Is highlighting code snippets on a programming blog or docs website even the same problem as highlighting inside an IDE?
Honestly no, not at all! Error tolerance, incremental parsing, and performance (the major constraints that justified the regular expression approach) just aren't as relevant. In the context of a static site generator or React component, it's probably safe to assume that the source code is syntactically well-formed. On the web, "syntax highlighting" just means rendering the whole thing to HTML in a single pass.
But mode-based pattern matching is the state of the art on the web anyway. The two big JavaScript syntax highlighting libraries today are highlight.js and PrismJS, each of which use their own nested regex grammar format. They're both fantastic libraries, and the product of an absolutely massive community effort to maintain grammars for all the languages they support. But tree-sitter proved that reasonably general parser generators are possible, and that they're a cleaner way to get fine-grained syntax highlighting, so it's natural to wonder if something like it can be adapted for the web.
One option would be to just use tree-sitter through WASM; web-tree-sitter does exactly this. But although WASM can run anywhere, using it in modern web stacks is still a pain - you have to load the WASM blob, which requires hosting and serving it to browsers, using WASM means waiting for async module initialization, and it makes server-side rendering difficult (Shiki, another popular web syntax highlighter, uses VS Code's TexMate library compiled to WASM, and suffers from this limitation).
So ideally we'd have a pure-JavaScript alternative. Fortunately for us, somebody has already done the hard part! Marijn Haverbeke (The CodeMirror Guy) has completely rewritten CodeMirror from the ground up for version 6, and spun out as a separate project an adaptation of tree-sitter called Lezer. Lezer is a parser generator system: it has its own syntax for writing .grammar files, but uses them to generate zero-dependency pure JavaScript LR parsers. From the reference page:
This system's approach is heavily influenced by tree-sitter, a similar system written in C and Rust, and several papers by Tim Wagner and Susan Graham on incremental parsing (1, 2). It exists as a different system because it has different priorities than tree-sitter—as part of a JavaScript system, it is written in JavaScript, with relatively small library and parser table size. It also generates more compact in-memory trees, to avoid putting too much pressure on the user's machine.
(I feel obliged to mention that Marijn's work has been very personally inspiring. The code he writes is incredibly principled and well thought-out; I felt like I connected with a clearer sense of software design just by reading through the CodeMirror 6 codebase.)
Anyway: Lezer parsers are the basis of syntax highlighting and other code analysis features in CodeMirror 6, but are also usable on their own. This is important because although CodeMirror is a fantastically well-engineered piece of software, it is also very opinionated about things — for example, it can't be server-side rendered, interacts with the DOM on its own terms, and requires a bit of boilerplate to use with React. But Lezer is a standalone zero-dependency system that can run anywhere, with or without the rest of CodeMirror.
This means we can use Lezer to build a simple, pure-JavaScript syntax highlighting system for React.
I've released a reference module implementing this as react-lezer-highlighter on NPM. Here's the entire source code!
import React, { createContext, useContext } from "react"
import { fromLezer } from "hast-util-from-lezer"
import { toH } from "hast-to-hyperscript"
import type { LRParser } from "@lezer/lr"
export const Parsers = createContext<Record<string, LRParser>>({})
export interface CodeProps {
language?: string
source: string
}
export const Code: React.FC<CodeProps> = (props) => {
const parsers = useContext(Parsers)
if (props.language !== undefined && props.language in parsers) {
const parser = parsers[props.language]
const tree = parser.parse(props.source)
const root = fromLezer(props.source, tree)
const content = toH(React.createElement, root)
return <code className={props.language}>{content}</code>
} else {
return <code className={props.language}>{props.source}</code>
}
}I personally don't like it when libraries vendor lots dependencies, so here I'm using a React Context called Parsers to that you have to populate yourself with Lezer parsers for the languages that you want to use. You can find the officially-maintained parsers as repos in the lezer-parser GitHub organization, search for third-party ones, or write your own.
That hast-util-from-lezer library is a separate utility module that performs the parse tree traversal and returns a HAST root. The HAST root it returns could also e.g. be serialized to HTML using hast-util-to-html. It produces a flat array of span elements each with (possibly several) classnames like tok-variableName, tok-punctuation, etc that it gets from Lezer. Here's its entire source code:
import { highlightTree, classHighlighter } from "@lezer/highlight"
import type { Element, Text, Root } from "hast"
import type { Tree } from "@lezer/common"
export function fromLezer(source: string, tree: Tree): Root {
const children: (Element | Text)[] = []
let index = 0
highlightTree(tree, classHighlighter, (from, to, classes) => {
if (from > index) {
children.push({ type: "text", value: source.slice(index, from) })
}
children.push({
type: "element",
tagName: "span",
properties: { className: classes },
children: [{ type: "text", value: source.slice(from, to) }],
})
index = to
})
if (index < source.length) {
children.push({ type: "text", value: source.slice(index) })
}
return { type: "root", children }
}Pretty neat! We have a functional synchronous syntax highlighter that works everywhere. I'm using it to render this webpage (go ahead and open devtools and look at the classnames on all the tokens in the code blocks!), and you can also check it out on GitHub. Feel free to use it in your next project, or just copy the ~100 lines and adapt them as you see fit.